压测背景:
LPWAN是当前物联网行业中最重要的技术之一,以年复合增长率90%的惊人速度增长。NB-IOT、LoRa、ZETA以及Sigfox是当前市场上主流的几种LPWAN通信技术。ZETALPWAN协议以超窄带、低功耗双向通信和多跳组网的特点,彻底改善了传统的LPWAN协议不足之处,大大增加了LPWAN技术在物联网应用的空间。
ZETag云标签是纵行科技基于ZETA技术开发的传感柔性标签,具有公里级超广覆盖,低功耗特性等优势,与同类技术相比,成本可降低至1/3-1/10,并能支持大容量并发,使用寿命最长可达5年。与此同时,ZETag云标签通过减小尺寸和功耗并改善性能来消除常规有源标签的闲置,除却物流仓储和货物追踪,还可作为一次性标签广泛应用在资产定位和危化、危废管理的万亿级市场。
目前,ZETag云标签已在京东物流、中国邮政、日邮物流、上海睿池、上海派链等上下游物流企业物流载具及贵重包裹上实现应用,也是全球首例在速递邮件上实现实时轨迹跟踪的服务的物联网云标签。
数蛙科技是工业物联网千万级设备接入与管理的专业平台提供商,目前业务场景已覆盖电力、交通、物流、工业制造等多领域的商业应用。
涛思时序数据库TDengine是目前针对时序数据库的性能最优的开源数据库平台,广泛运用于工业、电力、车联网、大数据领域。
数蛙科技结合纵行科技的ZETag云标签与涛思数据的高容量时序数据库,为物流领域未来高增长、高并发的物流标签场景,进行了1000万接入、百亿级时序数据的运营级全业务模拟压力测试。
ZETag物流标签组网如下:
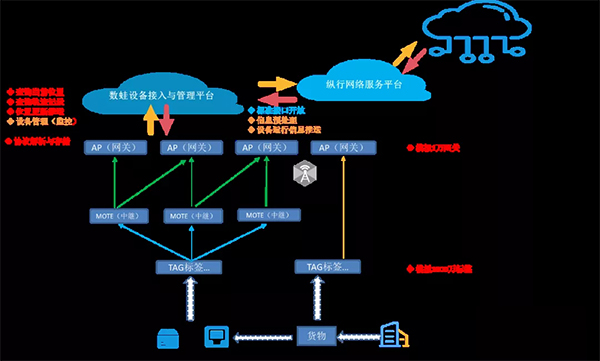
压测目的:
本次压力测试通过模拟1万ZETA AP、千万ZETA TAG标签的在线运行,精准高效完成ZETA AP、ZETA TAG的在线协议解析、解析数据实时入库、海量数据在线查询与展示等流程。同时,对真实物流业务场景进行抽象,实现批次ZETA TAG在不同线路上发生轨迹改变,移动过程中利用不同的ZETA AP实现定位。ZETA TAG在线运行过程中,每隔15分钟发送心跳包,被临近的单个或者多个ZETA AP报送至服务端。服务端会按照策略选择信号最好的上报数进行存库,并利用上报信号最好的AP对ZETA TAG进行定位。通过压力测试,判断当前应用环境情况下系统的负载能力,为今后应用范围扩大,用户量上升后,服务器扩容、升级等提供必要的技术支撑,及服务器规划等。
本次测试目的是为了验证基于数蛙连接与设备管理平台的ZETA物流跟踪管理能够实现千万级ZETATAG标签同时在线稳定运行、数据及时回传、正常入库、高效查库。
本次测试场景的压力与复杂度远高于真实场景,在保障ZETA物流跟踪当前业务可以正常开展的同时,也可以有效支撑ZETA相关业务应用的拓展与深化应用。
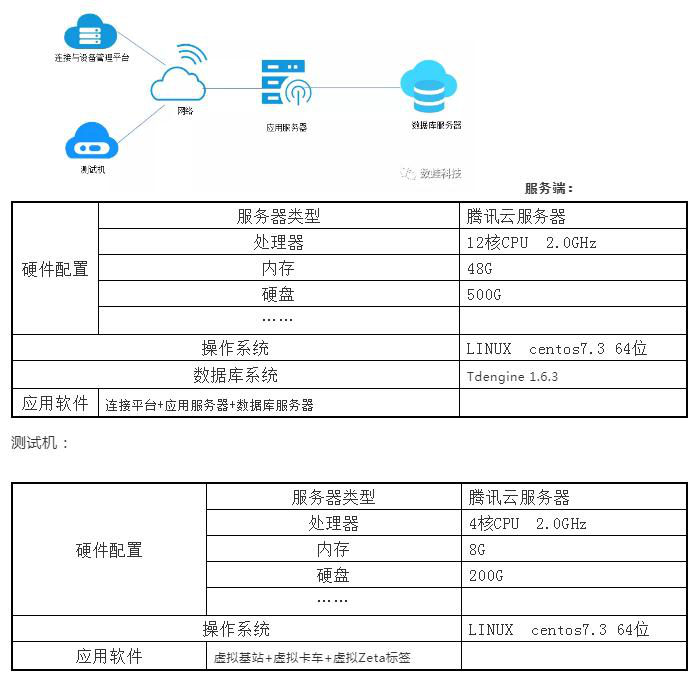
压测环境:
由于压力测试是对系统负载能力的测试,无法通过真实的环境来进行获取相关指标,因此通过测试机与测试服务,模拟1万AP、千万ZETA TAG与服务器高频数据交互,利用算法虚拟真实业务场景下实际的操作来进行测试。
测试机部署虚拟云设备服务,及进行压力测试的客户端机器,一般采用高配置的机器来进行测试。在压力测试过程中,一般忽略测试机对压力测试结果的影响。
压测场景:
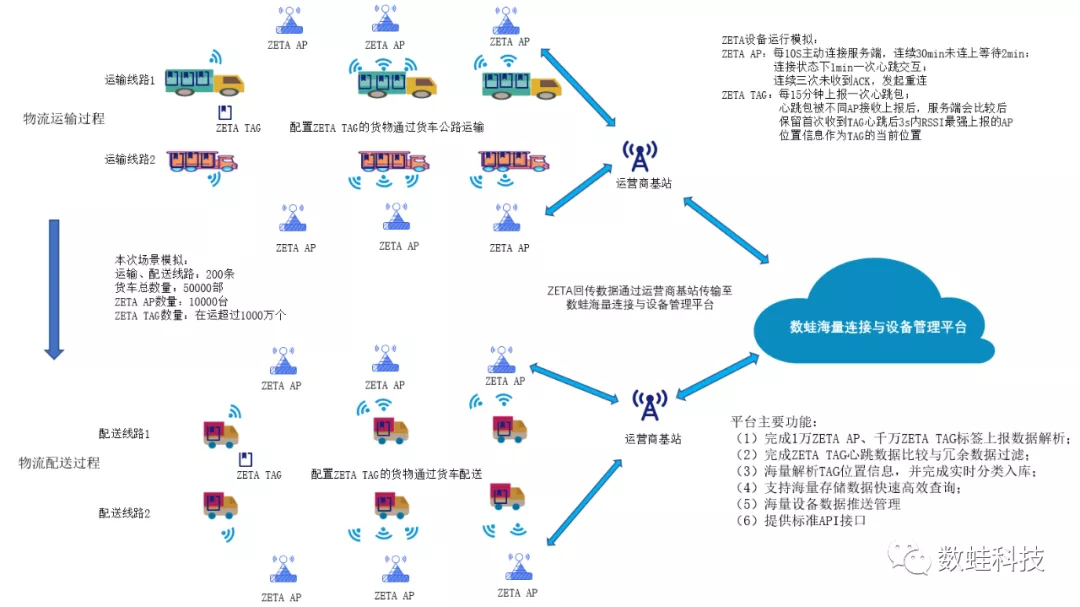
ZETA设备运行模拟:
ZETA AP:每10s主动连接服务端,连续30min未连上等待2min再次连接;连接状态下1min一次心跳交互;连续三次未收到ACK,发起重连。ZETA TAG:每15分钟上报一次心跳包;心跳报文被不同AP接收上报后,服务端会比较后保留首次 收到TAG心跳后3s内RSSI最强上报的AP位置信息作为TAG的当前位置。
客户端场景模拟描述:
运输、配送线路:本次场景模拟线路总计200条,线路可以配置。
运输车辆:本次场景模拟运输车辆50000部,货车会模拟真实物流场景在既定线路上进行移动,车上ZETAG标签随之移动。
ZETA AP:本次模拟10000台,每条线路上分布500台ZETA AP
ZETA TAG数量:本次模拟在运ZETAG1000万个,ZETAG随运输车辆移动,每隔15分钟的心跳报文被相邻的2-3个ZETA AP接收。
服务端业务描述:
1、每15分钟内完成千万在运ZETAG标签心跳数据包解析(加上冗余报文,每15分钟内解析心跳报文数量2000多万条);
2、完成ZETA TAG心跳数据比较与冗余数据过滤;
3、完成解析出的海量TAG位置信息实时分类入库;
4、支持ZETA TAG最新位置更新与轨迹查询;
5、每分钟完成1万ZETA AP的心跳报文解析、存储;
6、完成ZETA AP运行状态信息的接收与存储;
7、支持ZETA AP运行状态信息查询。根据测试系统中消息的业务场景情况,选取以下指标作为场景压力测试情况判断依据:
A、ZETA AP在线情况统计
B、ZETA AP在线率
C、在线ZETAG标签数量
D、ZETA标签解析包数量E、1/5/15分钟CPU平均负载
F、内存使用量压测技术:
系统监控服务端与客户端系统监控和业务数据监控采用
Prometheus&Grafana做统计与展示
时序数据监控 --- Grafana&TDengine监控插件(监控TDengine数据总量、丢包数以及增长速率)
系统指标监控 --- Grafana&&Prometheus监控插件,用node_exporter采集数据(监控CPU,内存,网络、存储四大指标)
业务消息监控 --- Grafana&Prometheus监控插件,业务层通过Prometheusclient实时统计各个消息路由节点上发包数、收包数以及丢包数等指标,业务层主要指标如下:

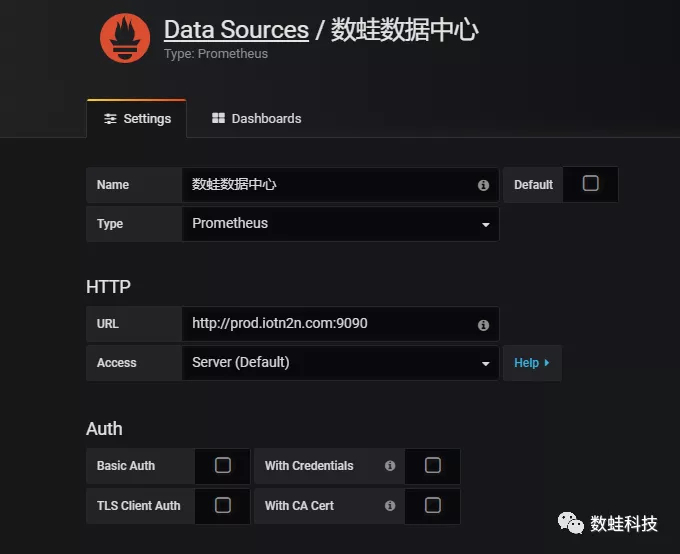
时序数据
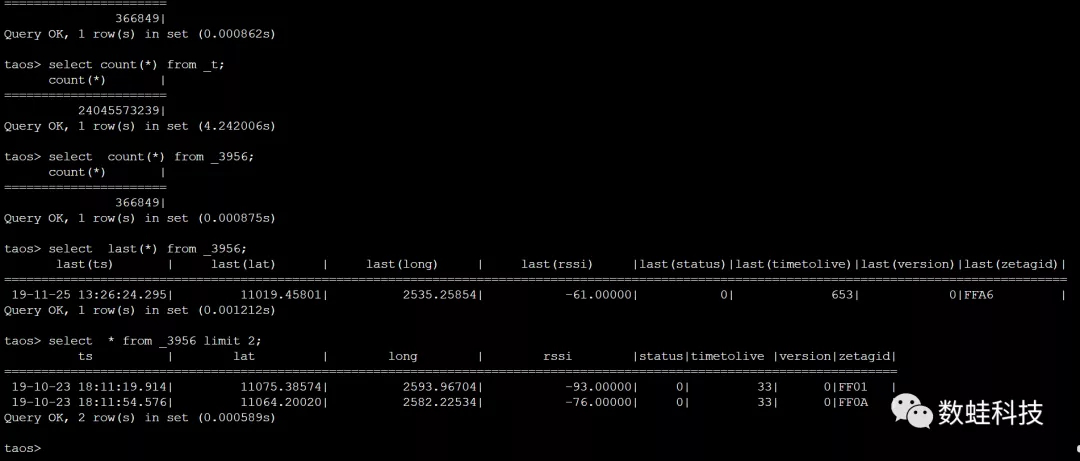
ZETag物流标签的地址域是4个字节,最高的一个字节是保留字节,本次压测的ZETag物流标签的实际地址域是3个字节,所以ZETag地址为FF XX XX XX,总计16,777,215个标签的地址,如果按照一个标签设备一个子表的方式设计,需要1600多万个子表。根据实测结果,Tdengine 1.6.3单机版本子表数量超过49万就极不稳定,很容易崩溃,但子表数量在10万以下具有良好的性能。所以子表设计采用了一种虚拟分组设计,将最低两个字节(总计65,535个子表)作为子表空间,每个子表存储一个字节(总计255个标签)的标签时序数据。时序数据模型设计:

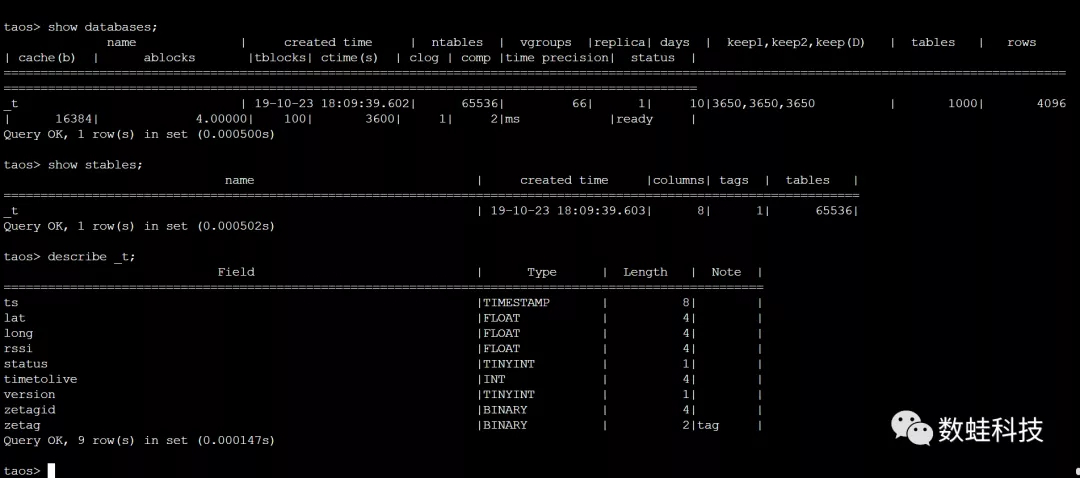
240亿数据存储空间占用230G磁盘空间
数据存储目录
时序数据入库示例:

时序数据入库策略:
本次模拟了1300多万的物流标签15分钟一个心跳,平均1.4万多的QPS,峰值QPS很容易超过Tdengine的入库QPS阀值,导致Tdengine崩溃。在消息路由层设计了一个基于令牌桶算法的消息缓存层进行削峰处理,在保证时序数据的顺序性的同时,也能让时序数据以比较平稳的速率批量入库。由于Tdengine没有提供erlang的连接池程序,最开始用默认的http客户端来入库,长时间运行不稳定,最后我们把Tdengine原生的c语言的连接池程序进行了改造,添加了mqtt订阅功能,通过mqtt协议来转发批量存库时序数据。时序数据出库策略:
由于对子表进行虚拟分组设计,查找任何一个物流标签数据的物流轨迹数据都有非常便捷的寻址算法,快速查找到用户层期望的时序数据,在百亿级数据规模的情况下,查询速度也可以到毫秒级。
ZetaEtag即时数据查询接口:/zeta/etag/{tag}
超时时间为5秒
随机读tag,数据库内数据58169933条
tag 生成方式:FF开头后六位随机生成
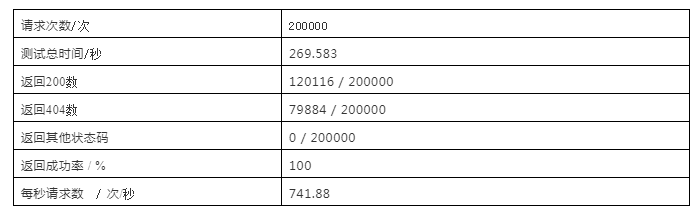
* 返回status code为200(找到目标tag)或404(找不到目标tag)两者都视为调用成功
ZetaEtag历史数据接口:zeta/etag/history/{tag}
超时时间为5秒对所有tag随机读,limit值为100,日期范围在合理范围内随机产生,数据库内数据58169933条
tag生成方式:FF开头后六位随机生成
日期生成方式:1569558137——1569579737间随机数
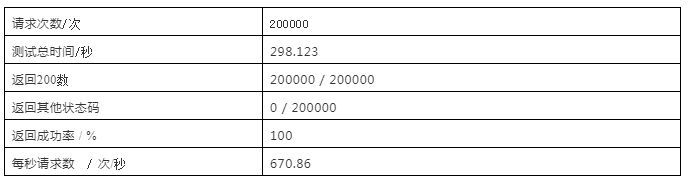
2019年10月份做压测报告时,没有记录240亿时的API统计,把去年的压测镜像恢复回来,240亿标签数据时的查询速度如下
消息路由
ZETag物流标签数据从数据产生到数据落库,1300多万ZETag标签 =》5万卡车进程=》1万AP基站客户端连接进程=》1万AP的服务端连接进程=》65535虚拟分组进程=》消息缓存调度进程 =》Tdengine的mqtt客户端=》Tdengine连接池存储进程,消息需要经过7次转发,每一跳都需要小心处理内存释放和消息堵塞问题。每15分钟有将近3000万-4500万消息的生产和消费,需要有非常好的GC处理机制。其中1万AP的服务端连接进程--》65535虚拟分组进程,这一跳消息转发速率没有固定的对应关系,两点之间QPS波动非常大,用开源的mqtt消息转发和消费组策略也非常容易导致消息堵塞和内存持续上涨。这里也还是得益于之前的虚拟分组设计,通过虚拟分组比较好的解决了这一跳的高效消息路由,同时也把这两点之间的消息转发的QPS峰值削的比较平。影子设备
本次测试模拟的是类似双11这样的物流标签轨迹最繁忙的场景,模拟了5万台卡车装满(200多件贴上ZETag标签的快递件)快递件,在200多条线路上飞奔,在行驶过程中不停切换AP基站,上报ZETag标签轨迹数据,满怀期望的用户时不时登录快递网站查看一下自己购买的货物到了何处。我们在系统中设计了5万个卡车影子设备,1万的AP基站影子设备和65535虚拟分组影子设备来处理这一较为复杂的业务场景。卡车影子设备承载了ZETA标签信息,线路位置信息和线路沿途的AP基站信息的交互,AP基站影子设备承载了ZEtag通信协议处理,虚拟分组影子设备承担了1300万ZETag标签的边缘计算和时序数据存储处理。任务调度
每15分钟有将近3000万-4500万ZETag标签消息的生产和消费除了需要良好的GC机制,同时也需要一个良好的任务调度机制。治大国如烹小鲜,每一个影子设备上面的任务调度处理细节非常关键,每一个小的偏差都会被乘以一个3000-45000万的系数放大,对任务调度质量要求是零缺陷。合理的分组策略(也即合理的影子设备设计)非常关键,可以从宏观上对系统资源进行削峰,在单个影子设备上进行完美的微操作,让每一个影子设备的任务调度策略达到零缺陷。
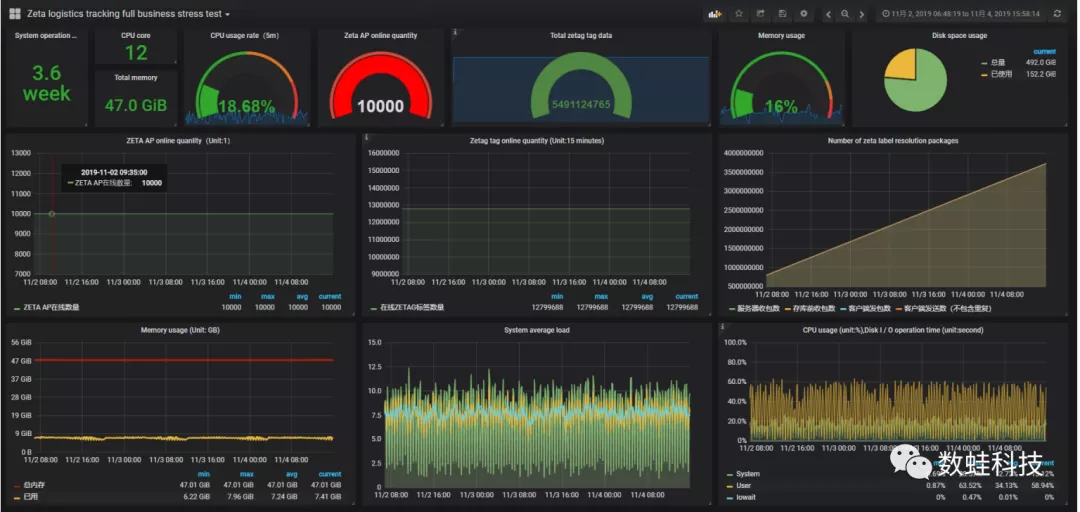
压测结果:
参考网站:
数蛙科技:http://www.iotn2n.com/
纵行科技:https://www.zifisense.com/
涛思数据:https://www.taosdata.com/
下一篇:警钟长鸣,纵行科技ZETag云标签技术助力危化品可视化管理